Data Products
The Real-to-Virtual Pipeline and Data Products
The monoDrive Real-to-Virtual system operates as a pipeline of computer vision and machine learning algorithms in conjunction with several deep learning networks in order to produce the final Unreal Engine assets. Each step in the pipeline outputs a data product that is then used by the next stage of the system. Each of these interim data products play an important role in the process of producing highly accurate simulation assets, but individually they can also be useful to the end-user for tasks like ground-truthing, labeling, and training.
This page goes through the currently available data products from the monoDrive Real-to-Virtual pipeline that is deployed to customers.
monoDrive Binary Data
The binary data that is recorded by the monoDrive Real-to-Virtual Data Logger consists of raw binary streams of data from the GNSS, Camera, and LiDAR systems that are part of the monoDrive Real-to-Virtual hardware. The current data logger saves:
- GNSS Data - Log files that can be played back in the VectorNav Control Center
- Ladybug 5+ Camera Streams - These are
.pgrstream files that contain all 6 cameras on the Ladybug Camera that can be played back with the Ladybug SDK
- Binary LiDAR Data - This is a raw stream of the packets sent from the
Velodyne LiDAR. The monoDrive Real-to-Virtual Data Logger provides utility
software in
utils/replay_lidar.vito play this data back so that it can be viewed in Veloview.
- Configuration Files - These are text files produced by the Data Logger software that contain orientation information for each sensor during parsing
- Timestamp Files - These contain the timestamps for each data acquisition iteration.
KITTI Formatted Data
After parsing the monoDrive Real-to-Virtual binary data with the monoDrive mapping-toolkit (currently only accessible by Real-to-Virtual customers), the data is formatted into the KITTI format. This format is used by several different benchmarks and algorithms for testing various vehicle perception stacks.
Segmentation
The semantic segmentation of images is the first step in processing data from
the monoDrive Real-to-Virtual system. The segmented data in the segmentation
folder contains grayscale images where each gray value represents a different
class of object. Segmentation is to the pixel level and performed on a
frame-by-frame basis and smoothed temporally.
-
The
rawfolder contains the one shot segmentation processing which yields good results for segmentation where the temporal frequency between images is not consistent. -
The
outputdirectory contains the same segmentation images, but they have been temporally filtered to help carry classifications between consecutive images to improve overall performance.
Redaction
Vehicle redaction is performed on the original camera data in order to improve
performance of various visual odometry algorithms that rely on static objects
in a scene for stable optical flow. The redaction folder contains images that
leverage the semantic information from the monoDrive segmentation to remove
vehicles by blurring them out in the imagery. This data set can help
dramatically improve visual odometry algorithms that rely on determining ego
motion from a forward facing camera.
Point Cloud Data
The cloud directory will contain all assets associated with processing and
fusion of point cloud data using monoDrive's point cloud classification and
stitching algorithms.
- There are several different paths formatted in the
TUM format
available in
.txtfiles. - KMZ Files that can be loaded for viewing the GNSS paths.
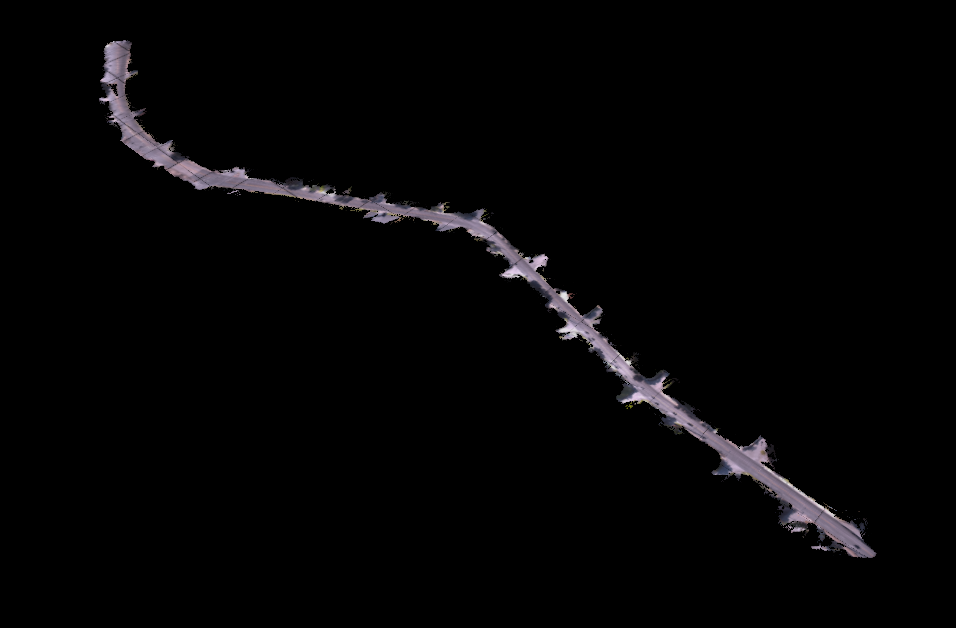
- A folder containing individual semantically colored point clouds created by fusing the LiDAR and camera image data.

- A folder containing fully stitched clouds for each semantic label (e.g. road, foliage, etc.)
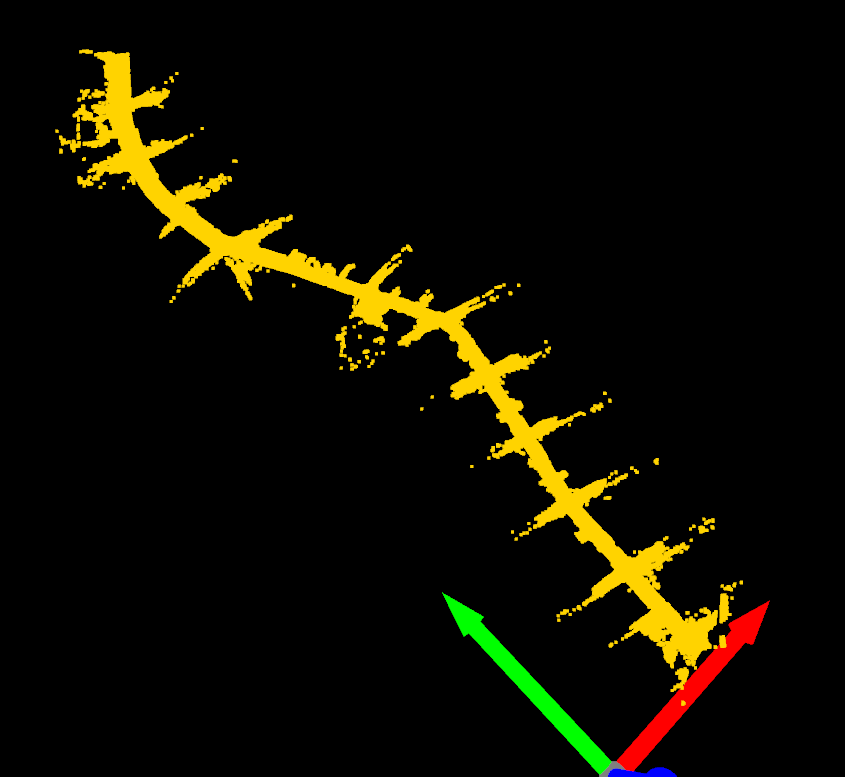
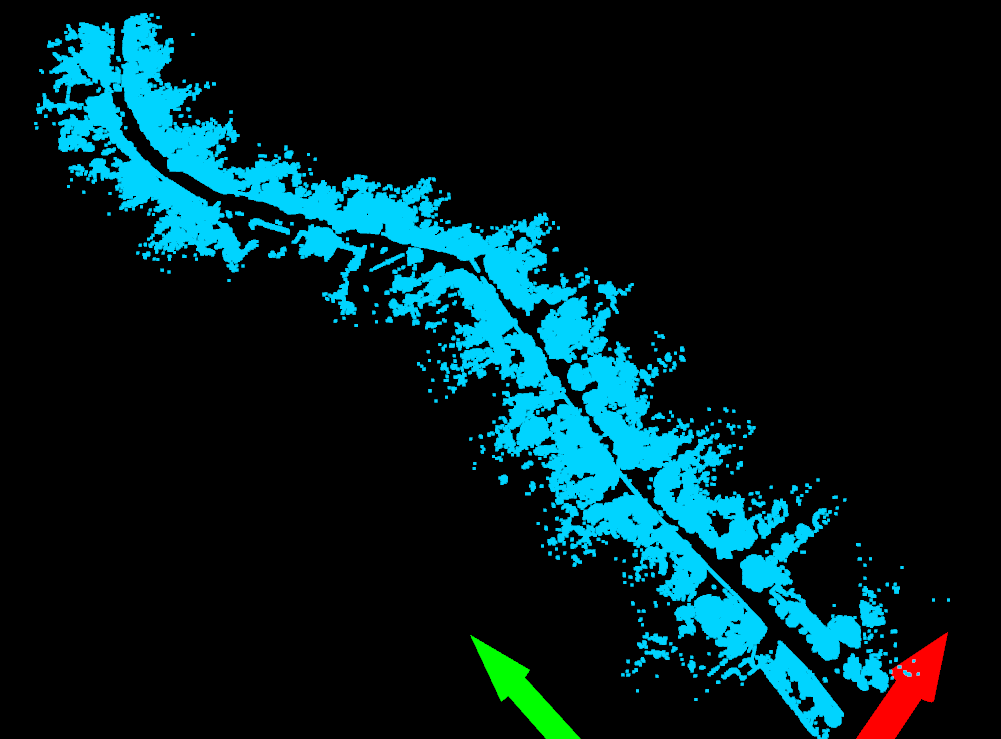
- The fully stitched clouds of all the data from the data set
- There is also full color stiched cloud data available in the
cloud_full_colordirectory
Object Detection
The object detection pipeline process annotates the segmentation images and encodes them with Run-length Encoding (RLE) masks. This is a compact way of representing the objects within an image for training and tracking. The JSON for the object annotations includes:
{
"_type": "ObjectAnnotation",
"class_label": 3,
"bbox": {
"_type": "BoundingBox",
"y": 197.0,
"x": 95.0,
"height": 11.0,
"width": 23.0
},
"mask": {
"_type": "RLEMask",
"size": [
422,
906
],
"counts": [
9,
413,
9,
...
]
},
"score": 0.9819106459617615
}
class_label: The label from the segmentation mask for this objectbbox: The bounding box in side of the original imagemask: THe RLE mask for the object in the image
The labels for the class correlate with the following table:
| Classification | Label |
|---|---|
| No Label | 0 |
| Car | 3 |
| Motorcycle | 4 |
| Bus | 6 |
| Truck | 8 |
| Fence / Guardrail | 5 |
| Traffic Light | 10 |
| Person | 11 |
| Bicycle | 12 |
| Building | 15 |
| Traffic signs | 20 |
| Terrain | 80 |
| Foliage | 85 |
| Sky | 141 |
| Street Light / Pole | 153 |
| Road | 175 |
| Sidewalk | 190 |
Tracking
The tracking directory contains all of the tracking information for recognized
objects throughout the data run. Tracking consists of identifying objects in
the detected objects JSON and predicting the motion between frames. If
multiple cameras are used and the proper geometry between cameras is known, then
tracking will work across cameras.
The JSON for the output of the tracking algorithms is similar to that of the object detection but correlates the objects temporally. For a given object, the tracking JSON looks like:
{
"_type": "TrackedObject",
"class_label": 3,
"instance_label": 1006,
"path": [
{
"_type": "Frame",
"timestamp": 1593178665.992904,
"index": 0,
"views": []
},
{
"_type": "Frame",
"timestamp": 1593178666.093764,
"index": 1,
"views": [
{
"_type": "View",
"camera": 0,
"bbox": {
"_type": "BoundingBox",
"y": 210.0,
"x": 428.0,
"height": 9.0,
"width": 16.0
},
"mask": {
"_type": "RLEMask",
"size": [
422,
906
],
"counts": [
180829,
3,
...
]
}
}
]
},
{
"_type": "Frame",
"timestamp": 1593178667.093764,
"index": 2,
...
For a single tracked object, the JSON defines:
class_label: The label from the segmentation for this type of objectinstance_label: The unique label for this particular objectpath: The list of frames that this object appeared in
For a single frame, the JSON defines:
timestamp: The UTC timestamp for the time the frame was acquiredindex: The index into the data set the frame was acquiredviews: The array defines the frames and RLE Mask in the frame that the object was tracked tocamera: The index of the camera the image was taken frombbox: The bounding box within the frame of the objectmask: The RLE encoded mask of the object to the pixel level
Static Object Detection
Once all of the objects of interest have been identified by the object detection
and tracked by the tracking algorithms, they are registered with world at
an instance level. The actors directory contains the JSON formatted data
that uniquely identifies each static object in the scene and provides world
location information for the object.
Each actor's JSON file should contain something similar to the following:
{
"_type": "StaticActor",
"class_label": 20,
"instance_label": 1035,
"tags": [],
"pose": {
"_type": "Pose",
"position": {
"_type": "Position",
"x": 41.97428340799148,
"y": -18.99226235561603,
"z": 0.6569370864010778
},
"quaternion": {
"_type": "Quaternion",
"x": 0.0,
"y": -0.0,
"z": 0.9644060037462335,
"w": 0.26442590632957996
}
}
}
class_label: Indicates the actors classification.instance_label: Uniquely identifies this actor in the data set.tags: Any tags that were applied to the actor for meta data.position: The x, y, and z coordinates of the actor in the world.quaternion: The quaternion that gives the rotation of the actor in the world.
Mesh
The mesh data generated by the Real-to-Virtual pipeline includes textured and
untextured meshes of the different assets produced by the data processing.
The textured meshes that are generated from the stitched point cloud data can
be found in the mesh/mesh_parts directory. These have been processed through
several meshing algorithms for optimal triangulation for each type of object.
The mesh/tiles directory contains the output from the monoDrive Direct Texture
algorithm. Here, each mesh is organized into an individual tile .obj file that
has been textured by projecting the imagery directly onto the mesh. When the
tiles are combined, the entire data set can be seen as a whole.